「記事が増えすぎて管理画面が重い…」 「全記事のタイトルとスラッグだけ一覧で見たいけど、プラグイン入れるのもな…」
ブログを長く運営していると、必ずこの壁にぶつかります。 ZIDOOKA!も記事数が300件近くになり、WordPressの管理画面だけでメンテナンスするのが限界になってきました。
そこで今回は、WordPress REST API を使って全記事データをぶっこ抜いて、管理用JSONを作った話をします。
結論から言うと、Node.js × REST API なら3秒で終わります。
なぜ REST API なのか?
最初は「Export All URLs」などのプラグインも検討しましたが、以下の理由で REST API を採用しました。
- 公式の正攻法である: WordPress標準機能なので、将来的に使えなくなるリスクが低い。
- ページネーション前提: 大量データでもサーバーに負荷をかけずに取得できる。
- JSONが扱いやすい: 取得後のデータ加工(分析、正規化、ツール連携)が圧倒的に楽。
実装のポイント:全件取得の「型」
REST API で全件取得する場合、ただ漫然とリクエストを送るだけでは失敗します。 以下の「型」を守るのが鉄則です。
1. per_page=100 で回す
WordPress REST API の1回あたりの取得上限は 100 です。
デフォルトは 10 なので、必ず per_page=100 を指定してリクエスト回数を減らします。
2. X-WP-TotalPages を信じる
「何ページまであるか?」は、レスポンスヘッダの X-WP-TotalPages に入っています。
これを正としてループを回せば、取りこぼしがありません。
3. 実際のコード (Node.js)
今回作成したスクリプトの抜粋です。
while (hasMore) {
try {
console.log(`Fetching page ${page}...`);
// per_page=100 で取得
const { data: posts, totalPages } = await wp.getPosts(page, 100);
// 必要なデータだけ抽出して軽量化
const processedPosts = posts.map(post => ({
title: post.title.rendered,
date: post.date,
modified: post.modified,
categories: post.categories.map(id => categoryMap.get(id) || id),
slug: post.slug,
tags: post.tags.map(id => tagMap.get(id) || id)
}));
allPosts = allPosts.concat(processedPosts);
// 最終ページまで行ったら終了
if (page >= totalPages) {
hasMore = false;
} else {
page++;
}
} catch (error) {
console.error(`Error fetching page ${page}:`, error.message);
hasMore = false;
}
}実行結果と「気づき」
スクリプトを実行すると、あっという間に全記事データが all_posts.json に保存されました。
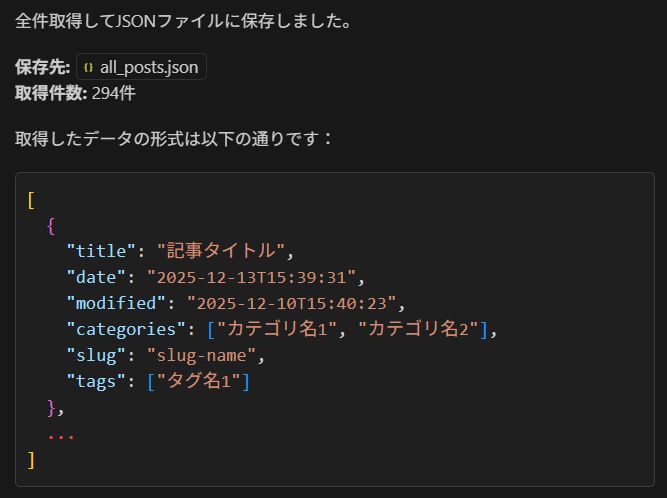
389件あるはずが、294件?
管理画面では「389件」と表示されているのに、取得できたのは「294件」でした。 バグか?と思いましたが、これは仕様通りです。
- 取得できたもの: 投稿 (
post) - 取得できなかったもの: 固定ページ (
page)、カスタム投稿タイプ
REST API の /wp/v2/posts エンドポイントは、あくまで「投稿」を取得するものです。
固定ページを含めて棚卸ししたい場合は、別途 /wp/v2/pages を叩く必要があります。
タグがスカスカ問題
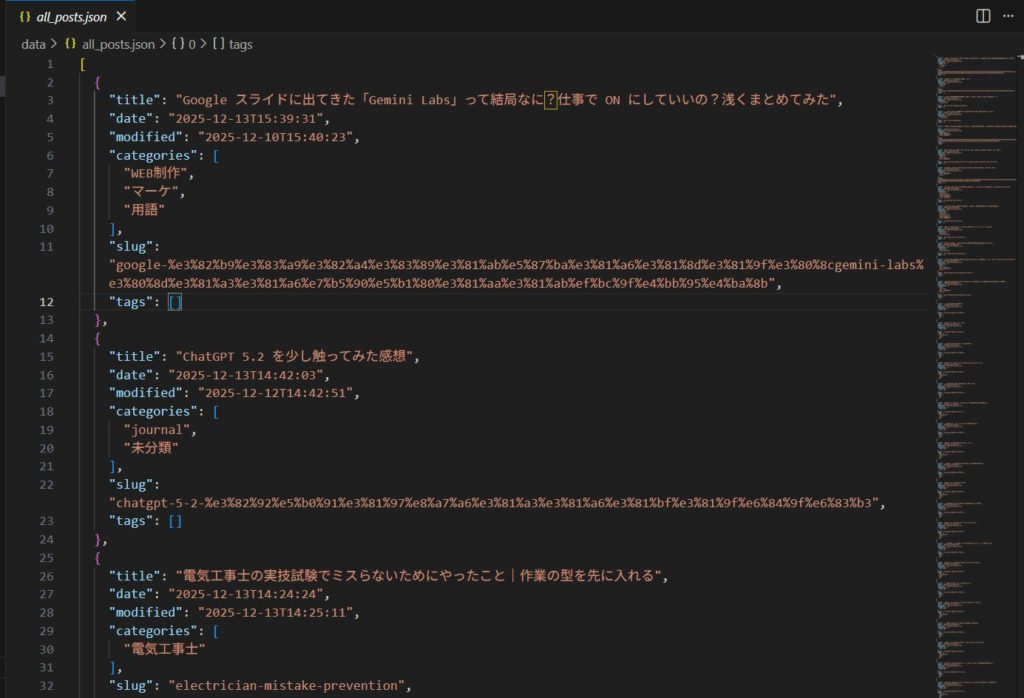
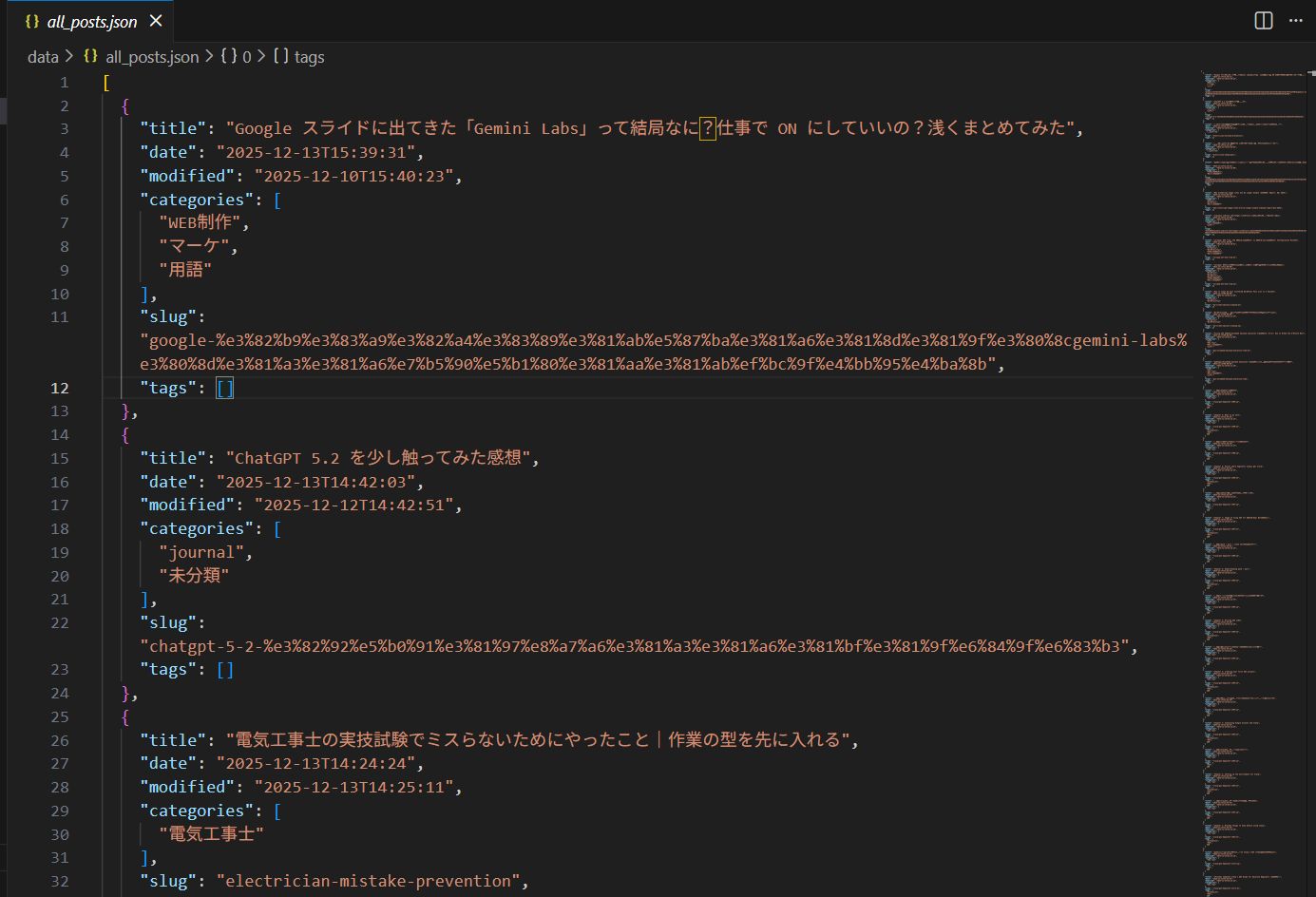
取得したJSONを見て気づいたのが、「tags が空配列 [] の記事が大量にある」こと。
管理画面で1記事ずつ見ていたら気づかなかったでしょう。 JSON化したことで、「タグ付け忘れ」や「カテゴリ設計の甘さ」が一瞬で可視化されました。
まとめ:JSON化は「攻めの管理」の第一歩
全記事をJSON化しておくと、ここから先の展開が無限に広がります。
- canonical 判定: 重複コンテンツの洗い出し
- 自動タグ付け: LLMにJSONを投げてタグを提案させる
- リンク切れチェック: 全スラッグと照合して孤立記事を発見
「管理画面が重い」「記事が増えて把握しきれない」という方は、ぜひ REST API での棚卸しを試してみてください。 一度JSONにしてしまえば、こちらのものです。